追源码的平凡之路

在斯坦福大学, 乔布斯做了一场我认为他最精彩的演讲。他讲的第一个故事是 connecting the dots,这也是贯穿他一生非常重要的思想。
你不可能充满预见地将生命的点滴串联起来;只有在你回头看的时候,你才发现这些点点滴滴之间的联系。所以,你要坚信,你现在所经历的将在你未来的生命中串联起来… 正是这种信仰让我不会失去希望,它让我的人生变得与众不同。
我不禁在想:我的编码以及架构生涯中,那些点是什么,又终将会连成怎样的线?
十年前刚进入 IT 行业的时候,我是一个很普通的工程师,脑袋也不灵光,工作老是得不到要领,而我的同学智商很高,他看一次代码基本就会写了,我得花很长时间去消化吸收,我对自己能不能在这一行生存下去都产生了质疑。
没有办法,只能笨鸟先飞,当遇到问题的时候,我都抱着死咬不放的心态去寻找最佳解决方案。洗澡的时候、吃饭的时候、甚至上厕所的时候都会去思考。很自然的,"追" 源码也成为我程序人生的一部分。
我阅读过很多源码,和大家分享几个对我职业影响比较大的源码追寻经历。
01 数据库连接池 Durid
这是在2013年,我负责重构一个彩票算奖服务,原有代码是 C# 版本的,每次计算订单金额需要耗费 2~3 个小时,很多用户反馈体验很差,因为收到奖金很晚。
我当时采用 Druid 作为新项目的数据库连接池,重构后效果很明显,算奖性能提升到了原来的 10 倍。
不过,有一个问题是:每天第一次数据库请求总会报连接错误。当时我也不怎么会看源码,就直接给 Druid 的作者温少(也是 FastJson 作者)发了一封邮件:
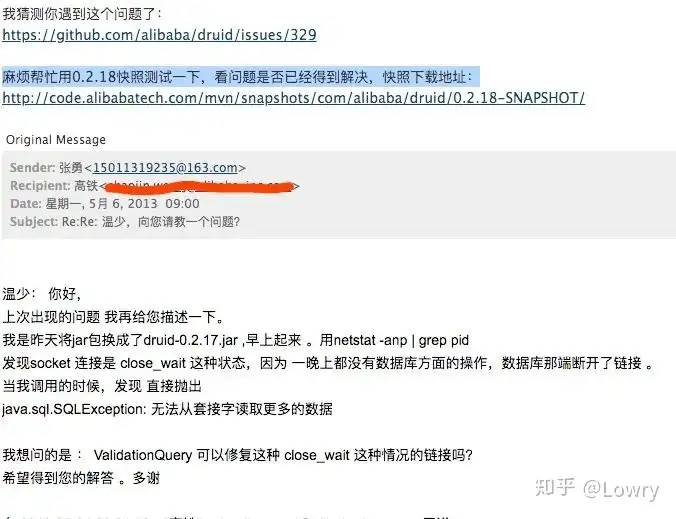
温少给我回复了邮件,我马上翻看源码,发现我配置的连接心跳有问题。核心点在于连接池每隔一段时间就会发送心跳包到数据库服务器,而数据库为了节省资源,会关闭掉长期没有读写的连接。
这次简单的源码之旅给了我很大的激励,也让我更加关注技术背后的原理。
1、精神层面:向别人请教问题是会上瘾的。 2、技能层面:理解连接池的实现原理。druid是基于数组实现的,后来用到的 jedis 连接池基于 commons-pool 实现的,netty 连接池是基于 FixChannelPool 实现的。 3、架构层面:客户端和服务端的长连接通信需要考虑心跳。类似 druid 连接池发送心跳的机制,以及 netty 中的 idleStateHandler。
02 分库中间件 Cobar
还是在 2013 年,当时移动互联网大潮奔涌而来,各大互联网公司的数据爆炸般的增长。
我曾在 JavaEye 上看到淘宝订单的技术人员分享他们分库分表的帖子,顿时觉得如获至宝,可惜受限于篇幅,文章没讲很细节的原理,总感觉隔靴搔痒。
没曾想到不久后阿里将 Cobar 开源了,用 Navicat 配置好 Cobar 信息,就像连单个 MySQL 一样,而且数据会均匀地分布到多个数据库中。这对于我当时还很孱弱的技术思维来讲,简直就像三体里的水滴遇到人类舰队般,给了我很大的刺激。
因为对分库分表原理的渴求,我花了大约 3 个月的时间把整个 Cobar 的核心代码抄了一次。真的是智商不够,体力来凑。
但光有体力是真的不够,经常会陷入怀疑,有些地方还是看不懂,边抄代码边学习好像进步没那么明显。那好,总得找一个突破口吧。
网络通讯是非常重要的一环,因此我决定把 Cobar 的网络通讯模块剥离出来,去深刻理解使用原生 NIO 实现通讯的模式。剥离的过程同样很痛苦,但我有目标了,不至于像没头的苍蝇,后来也就有了人生第一个 GitHub 项目。
在写 NIO 工程的同时,我还学习到了 Maven 的 Assemble 打包模式,这个现在听起来很简单,但在 2013 年还是以 Tomcat 部署 war 包占主流的年代,让当时的我眼前一亮。
追 Cobar 的过程中,我也找到了和阿里大牛面对面交流的机会,虽然我资质驽钝,但这位大牛对我的问题耐心解答,似乎打通了我的任督二脉。因此,这次经历说成是我编码生涯中最重要的一次经历也不为过。

后来在艺龙网工作,和艺龙做数据库中间件的架构师沟通时,因为我有研究 Cobar 源码的底子,理解他的思路也很快。另外,也帮助他找到了分布式事务的一个 Bug。
03 阿里的消息中间件 MetaQ
2015年我加入神州专车,那个时候神州专车处于上升期,各个系统遇到了较大的瓶颈。MetaQ 在那个时期发挥了很重要的作用,相关引申的知识点也很多。
3.1 广播消息在推送系统中的使用
当时我们使用的 MetaQ 是庄晓丹在 GitHub 开源的版本。2016年初,我 checkout 了 MetaQ 的源码,边理解业务边深入理解它的机制。
很有幸地和架构部的同事讨论了专车推送的设计方案。最开始的时候,我们也是使用极光推送,后来因为定制化的需求越来越多,因此决定自研推送系统。
那服务器如何推送消息到每一个连接的专车 APP 呢?方案很简单:采用 MetaQ 的广播模式就可以实现这个功能。
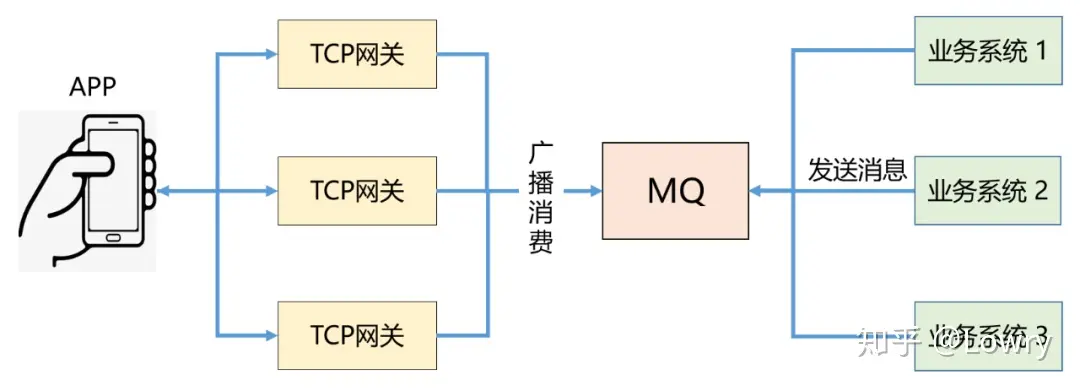
1、业务系统推送消息到 MetaQ 2、TCP 网关广播模式消费 MetaQ 的消息 3、TCP 网关获取当前服务器所持有的 Session 会话,推送数据给 App
后来,我仔细研读了京东京麦系统的 TCP 网关设计,关于推送方面的实现和我们上面的方案非常相似。
2018年,我服务的电商公司研发直播答题系统,我用这个方案又实现了推送题目的功能。
3.2 ZK 崩溃引申的一连串知识
我们都知道 MetaQ 依赖 ZooKeeper 来实现负载均衡。突然有一天,专车整个 ZK 集群 down 掉了。架构负责人修改了 ZK 的 JVM 参数,问题貌似解决了,但疑问随之产生了。
MetaQ 和服务治理共用一套 ZK 集群合适吗?
阅读 MetaQ 源码后,我发现 MetaQ 在消费者很多的情况下,启动时会频繁的争抢锁,另外消费的过程,也会对 offset 频繁的修改。在 Topic 数量增多,partition 数量增多的情况下,MetaQ 对 ZK 实际上是有写压力的。
后来,神州架构部确实也是将 MetaQ 的 ZK 集群和服务治理的 ZK 集群分开了。当然迁移也是有技巧的,这里就不展开了。
ZK 作为神州体系的注册中心是否有瓶颈?
ZK 会存储各个服务的 IP 和端口,以及对外暴露的方法。随着专车系统的服务越来越多,ZK 真的可以承受得了吗?后来,公司领导邀请了京东的研发同学来给大家答疑。
京东的注册中心服务信息用什么实现的呢?京东同学的回答是:MySQL。我在旁边听得目瞪口呆,什么?MySQL?后来,淘宝中间件博客出了一篇文章:阿里巴巴为什么不用 ZooKeeper 做服务发现?
当数据中心服务规模超过一定的数量,作为注册中心的 ZooKeeper 很快就会像驴子一样不堪重负。
后来我参考张开涛写的一篇博客以及在 GitHub 上零落的 JSF 代码, 手撸了一个 AP 模型、客户端使用 BerkeleyDB 的注册中心。
我们也知道 2019年,阿里在 SpringCloud 生态上发力,Nacos 诞生了。Nacos 同时支持 AP 和 CP 两种模型,开源世界的选择更有多样性了。当我们使用 ZooKeeper 的时候,一定要注意集群规模和使用场景。
04 任务调度系统 XXL-Job
时间已经到了 2018 年,技术部需要一个可靠的任务调度系统。最开始使用的是 XXL-Job,但不知道怎么搞的,老是使用遇到有问题。从追源码到优化改造共经历了 3 个阶段。
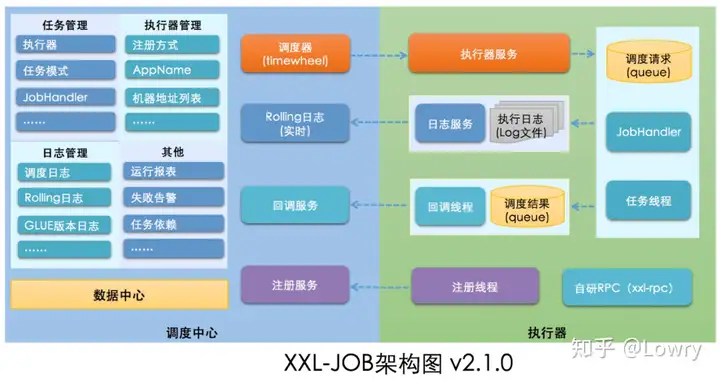
第 1 阶段,我看了 XXL-Job 的源码后,第一直觉是「简单」。因为作者已经最大限度的将这个系统做成了开箱即用,去掉了 Quartz 的集群调度模式,自研基于数据库的调度器。
但当前公司已经有自研的 RPC 服务,让其他团队配合 XXL-Job 添加JobHandler 好像也不太容易。所以最开始,我修改了调度器的代码,使用了公司的 RPC 来执行,只不过将 XXL-Job 的 JobHandler 替换为公司 RPC 的ServiceId。运行起来还行,能满足公司要求。
第 2 阶段,为什么我想再优化一波呢?因为当前的 RPC 调度是同步执行,不支持异步,假如 RPC 执行任务很长,那么 XXL-Job 的调度线程就会被阻塞。
我找到了美团的朋友,向他请教他们公司是如何设计任务调度系统的。他给我演示了美团任务调度系统 Crane 的执行过程,考虑到保密他仅仅给我讲了其中的原理。我根据他的描述做了如下架构设计:

Schedule-Client 收到调度请求后,会将任务丢到线程池中异步执行,同时立马返回给调度服务器,这样就不会阻塞了。
第 3 阶段,光有架构设计没用,工程上如何做到更优雅的实现呢? 我想到了阿里云的schedulex,假如我是一名阿里云的开发者,我会怎么设计一个好的任务调度系统以支持每天千亿级别的任务调度呢?
我翻看了 schedulex 的开放文档以及 client 端源码,想不到真的是宝藏。schedulex client 里包含如下几个亮点:
1、RPC 调用类似 RocketMQ remoting 2、任务调度通过 RPC 触发,有统一的注册中心(NameServer 模式) 3、支持多端口启动,以防当前端口启动失败 4、任务执行和任务调度的线程池做了隔离
借鉴这些优点,我很快完成了工程实现,技术同事们对这个改造还算满意。但我深知,当前的系统还有两个待解决的问题:
1、任务调度重度依赖数据库, 当真正有 10 万、20 万级别的任务的时候,任务的分配以及调度的触发肯定会有瓶颈。 2、当系统是容器的时候,是否可以正常使用?
于是,今年年初我在 GitHub 上写下了自己相对完整的一个任务调度系统,将 Quartz 替换成了时间轮,将任务触发改成服务端推送模式。
在写任务调度的过程中,实际上也是不断超越自己的过程,我想把它做成一个可以和行业对标的作品,就必须向业界最先进的技术产品以及优秀的同行们学习。
05 写在最后
回顾那些追源码的点滴,心潮澎湃,久久不能平复。它们是我架构师之路最美好的记忆。
乔布斯的演讲里提到:工作将占据你生命中的很大一部分,只有从事你认为具有非凡意义的工作,方能给你带来真正的满足。而从事一份伟大工作的唯一方法,就是去热爱这份工作。
专注当前做的事情,并且把每件事情做到能力范围内的极限,也许此时没有那么大的成就感,但在未来的某个时间节点,你可能突然就有一种「蓦然回首,那人却在灯火阑珊处」的后知后觉。
亲爱的程序员朋友,爱你所选,全情投入,相信你必有所得。
